
Claude Opus 4.6 — оновлення моделі Anthropic із акцентом на кодування та сесії. У релізі зазначають, що вона планує уважніше й довше веде агентні задачі. Також підкреслюють сильніші code review і дебагінг, тобто самоперевірку. Просто кажучи, модель частіше ловить власні помилки ще до того, як їх побачите ви. Її позиціонують і для офісних задач, повідомляє vv.com.ua.
«Ціную, коли модель сама зупиняється й просить перевірити ризик», — коментує тімлід.
Кодування і рев’ю: більше дисципліни
Opus 4.6 описують як модель для задач із кількома кроками та перевірками. Вона швидше проходить прості частини і не губить нитку, коли треба повернутися до складного. У великих репозиторіях це знижує ризик “побічних ефектів” у змінах. Менше дрібних правок після відповіді — більше часу на рішення. Особливо в довгих сесіях.
1M контекст і менше “context rot”
Вперше для Opus-класу заявлено вікно контексту 1M токенів. Реліз також говорить про кращий пошук релевантного у великих наборах документів. Наголошується на меншій деградації якості в довгих діалогах. Як приклад наведено MRCR v2 (8-needle, 1M): Opus 4.6 має 76%, тоді як Sonnet 4.5 — 18,5%. Це подають як доказ користі довгого контексту.
Бенчмарки: ключові заяви
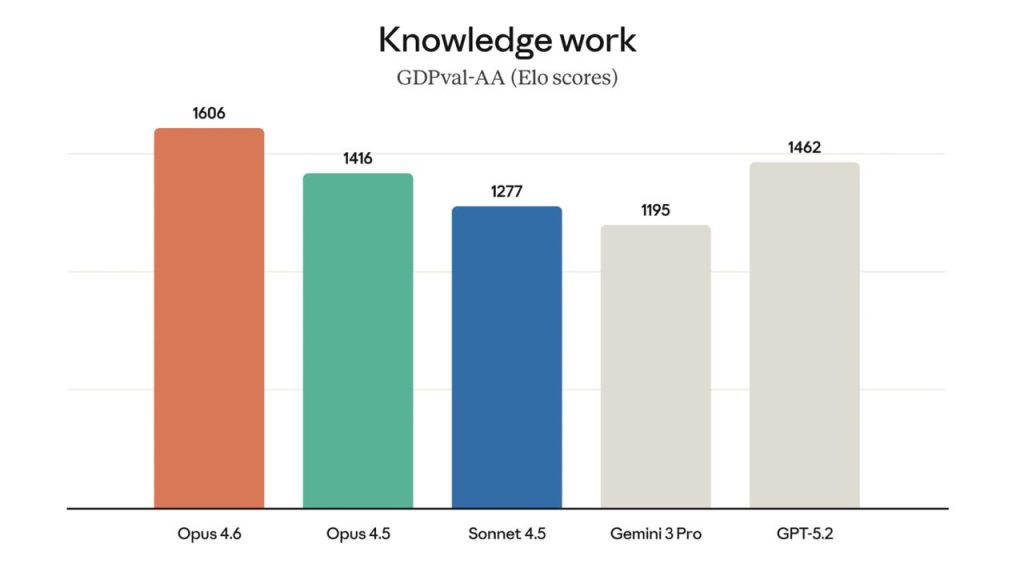
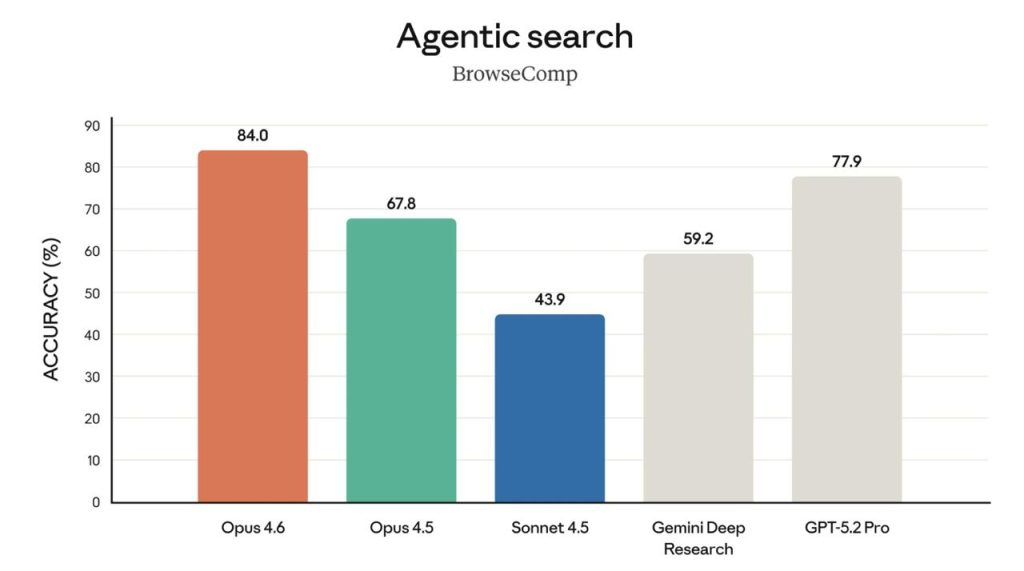
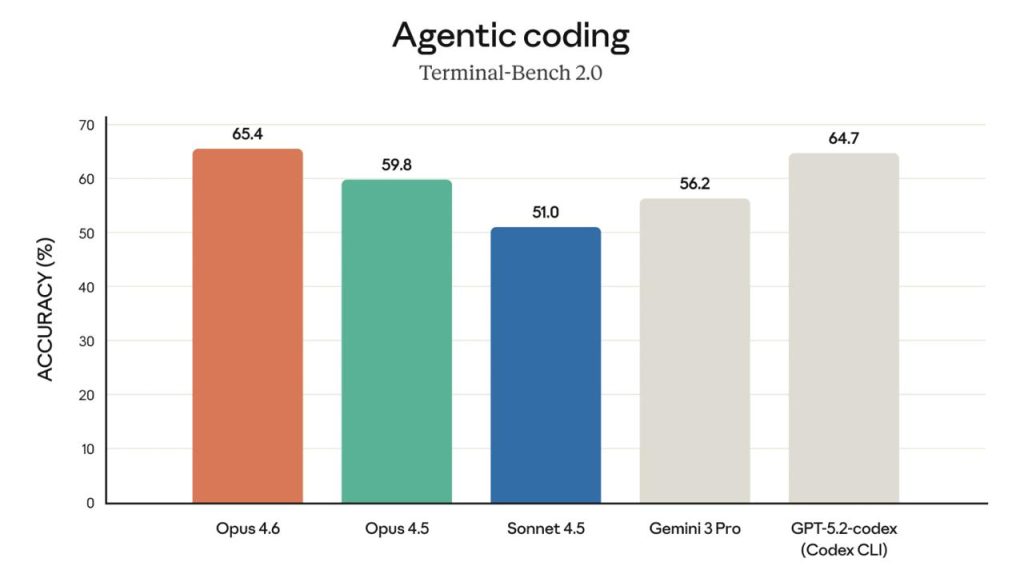
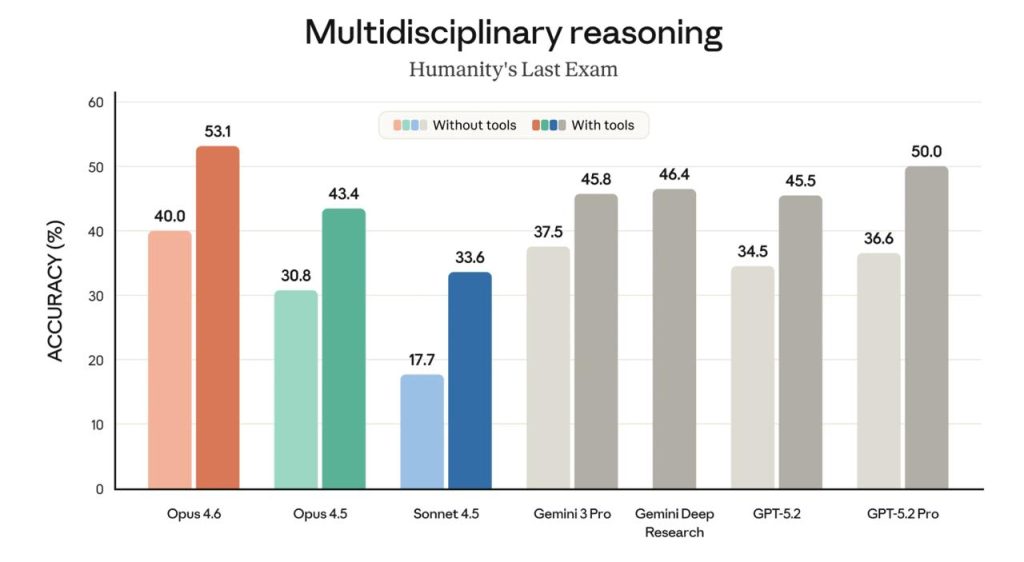
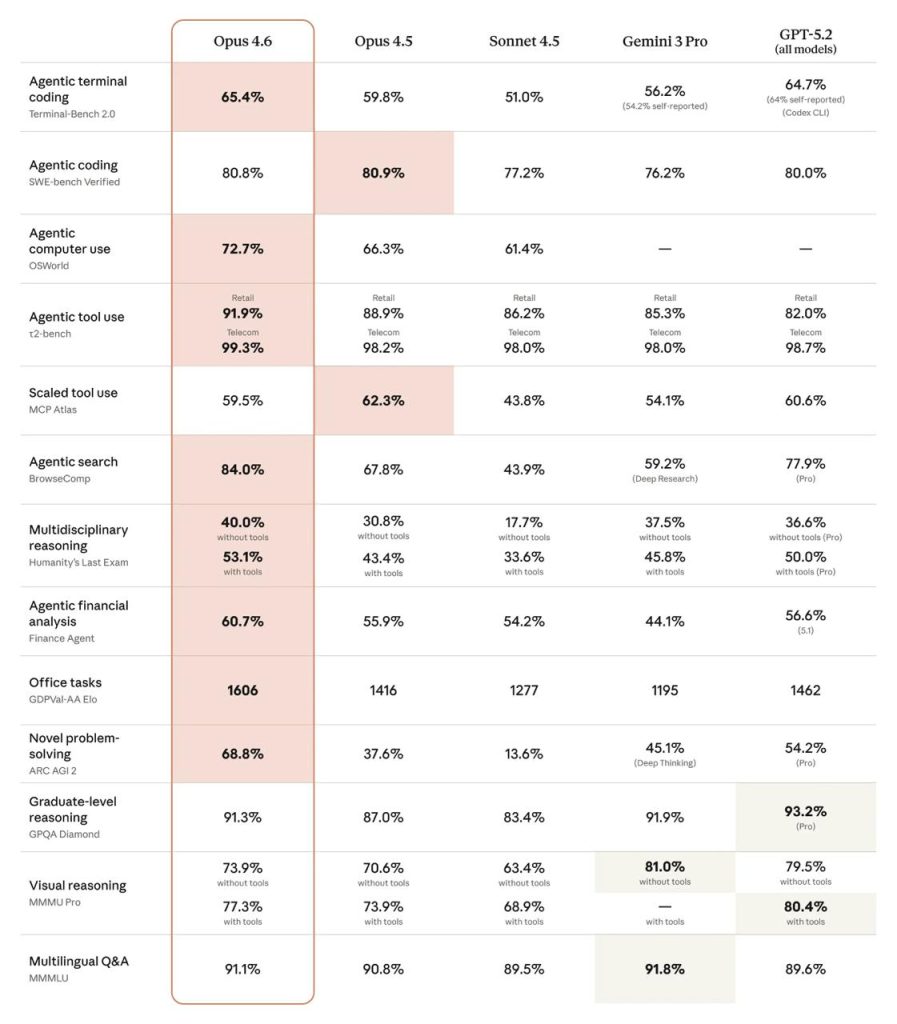
У матеріалі Opus 4.6 називають state-of-the-art. Згадується найвищий результат у Terminal-Bench 2.0 (agentic coding). Також пишуть про лідерство в Humanity’s Last Exam. На GDPval-AA модель, за заявою релізу, випереджає OpenAI GPT-5.2 приблизно на 144 Elo і Opus 4.5 — на 190 Elo. Окремо виділяють BrowseComp для пошуку онлайн.
| Тест | Фокус | Заява |
|---|---|---|
| Terminal-Bench 2.0 | agentic coding | топ |
| Humanity’s Last Exam | мислення | лідер |
| GDPval-AA | робота знань | +144 Elo |
| BrowseComp | пошук | топ |
API-оновлення: effort, compaction, adaptive thinking
В API додали рівні effort (low, medium, high, max) та параметр /effort. Це потрібно, щоб зменшувати “overthinking” там, де важливі швидкість і ціна. Описано adaptive thinking, коли модель сама вирішує, чи потрібне розширене мислення. З’явився context compaction (beta): старий контекст підсумовується, коли діалог підходить до межі. Також заявлено до 128k токенів у відповіді та преміум-ціна для промптів понад 200k токенів.
«Ці ручки дають контроль над швидкістю, вартістю і якістю», — пояснює архітектор інтеграцій.
Excel, PowerPoint і швидка перевірка придатності
У релізі наголошують, що модель підходить для досліджень, фінансових аналізів і роботи з документами. Заявлено оновлення Claude в Excel і вихід Claude в PowerPoint у прев’ю для Max, Team та Enterprise. Також з’являються agent teams у Claude Code (research preview), де кілька агентів працюють паралельно. Перед тестуванням корисно звірити свій сценарій із типовими випадками використання. Нижче — короткий чеклист, який допоможе швидко зорієнтуватися.
- Довгі агентні задачі з кількома ітераціями правок.
- Великі документи і потреба стабільно витягувати деталі.
- Критичні рев’ю, дебагінг і самоперевірка помилок.
- Автоматизація в Excel і презентації в PowerPoint із даних.